
Why Solana Needs Faster Data Propagation
TL;DR
Solana is renowned for its high throughput and sub-second block times, but speed isn’t just about how fast a leader can produce a block – it’s also about how quickly that data reaches every validator. In a network where slots last only ~400ms, even a 100ms delay in block propagation can be significant. This article dives into Solana’s block propagation stack (Turbine, ShredStream, JetStreamer), the limitations it faces, and why further accelerating data propagation (with RLNC-based propagation) is critical for Solana’s future scalability and reliability.
TL;DR
- Solana’s block propagation speed is critical: With ~400ms slot times, even small delays in data reaching validators impact performance, fairness, and network resilience.
- Turbine is fast, but not flawless: Its UDP-based, stake-weighted, erasure-coded tree helps distribute data quickly, but introduces challenges like unequal data access, packet loss, and limitations at higher throughput.
- JetStreamer shows what’s possible: Streaming 2.7M+ TPS from historical data proves Solana’s architecture can scale further, if propagation bottlenecks are addressed.
- mump2p brings RLNC-based gossip to the table: Unlike Turbine’s fixed routing, RLNC lets nodes forward partial, recoded data, cutting latency, boosting fault tolerance, and making propagation more efficient.
- Faster, fairer, and more reliable propagation is key to Solana’s future: Innovations can offer a path to greater scalability, decentralization, and robustness.
Turbine: Solana’s Block Propagation Backbone
Solana’s core innovation for moving data fast is Turbine, a block propagation protocol inspired by BitTorrent. Instead of sending whole blocks to every node (which would overwhelm bandwidth), a leader splits each block into many small chunks called shreds and distributes them in a layered fanout network.
- Shredding and Erasure Coding: When a validator becomes leader, it splits the block into data shreds, which are small packets sized to fit within the network’s Maximum Transmission Unit (MTU), typically around 1232 bytes on Solana. This ensures efficient transmission across UDP. After producing the data shreds, the leader applies Reed-Solomon erasure coding to generate coding shreds - additional parity chunks derived from the data shreds. These coding shreds provide redundancy: if some data shreds are lost in transit, any validator can still reconstruct the full block as long as it receives enough data + coding shreds to meet the recovery threshold.
- Multi-layer Tree Distribution: Turbine organizes validators into a multi-hop tree, where the leader sends distinct shreds to 200 peers - a fanout parameter known as DATA_PLANE_FANOUT. Each of these peers then forwards their assigned shreds to the next layer of nodes. This layered propagation structure significantly reduces the leader’s outgoing bandwidth burden, while ensuring rapid and parallelized block dissemination. By distributing the work across layers, Solana maximizes bandwidth utilization and minimizes single points of failure.
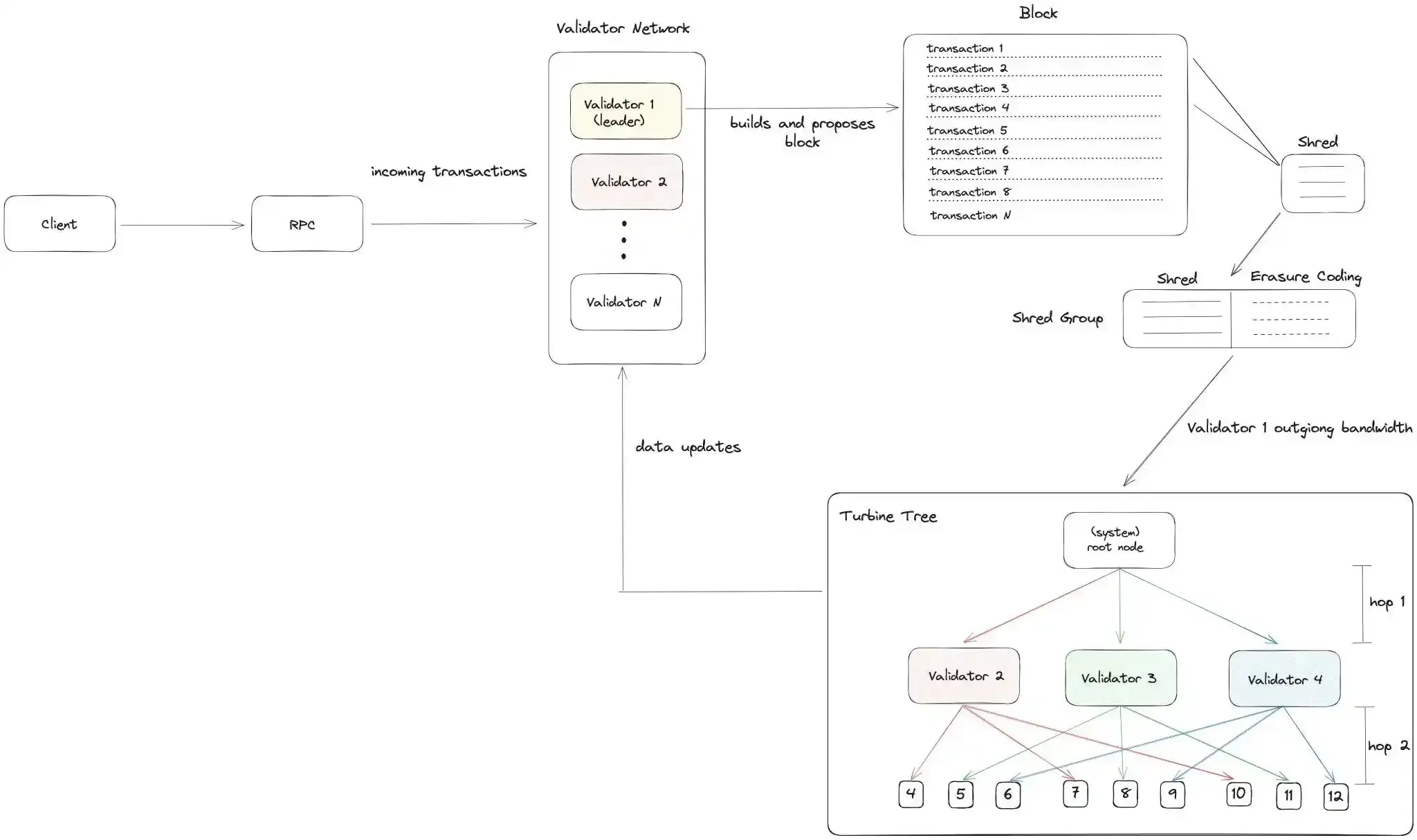
- Stake-Weighted Routing: Notably, Turbine’s design includes a stake-weighted topology. Validators with higher stake are prioritized to receive shreds earlier in the propagation chain. In practice, the “validators with higher stake receive the shreds faster, allowing for earlier voting and block processing”. This helps the network confirm blocks quickly (since validators with large stake vote sooner), but it also means smaller nodes might consistently be a few steps behind in receiving data.
- UDP Transport: Solana historically uses UDP for transmitting shreds, unlike Ethereum which gossips blocks over TCP. UDP’s lightweight nature lets Solana blast out shreds with minimal overhead, maximizing throughput. The trade-off is that UDP doesn’t guarantee delivery – some shreds (packets) can be dropped in congested networks. Turbine mitigates this with redundancy (erasure-coded shreds) and by having multiple validators forward data, but it’s not perfect under real-world conditions. There is ongoing work to support QUIC. QUIC preserves the speed advantages of UDP while adding features like congestion control and stream multiplexing. Solana is gradually transitioning some parts of its networking stack to QUIC to improve reliability without sacrificing throughput.
The result: Turbine enables high-speed data propagation designed specifically for Solana's throughput of 50,000+ transactions per second. Running a Solana node requires significantly more bandwidth than Ethereum (which needs roughly 25 Mbps) because Solana processes far more transactions. But this bandwidth gets put to productive use—Solana's architecture fully utilizes available bandwidth to accelerate data transmission. In simpler terms: Solana moves massive amounts of data very quickly, and Turbine's structured design makes this approach practical and sustainable for validators.
ShredStream: Streaming Blocks in Real-Time (Reducing Latency)
Even with Turbine, network propagation isn’t instantaneous. Some validators are geographically farther apart or just end up lower in the tree, so they see new blocks a few hundred milliseconds later than the leader. For most users that delay is negligible, but in certain contexts (trading, fast block producers) every millisecond matters. This need for low latency block delivery gave rise to ShredStream - a complementary solution by Jito Labs (and similar services by others) to accelerate data delivery.
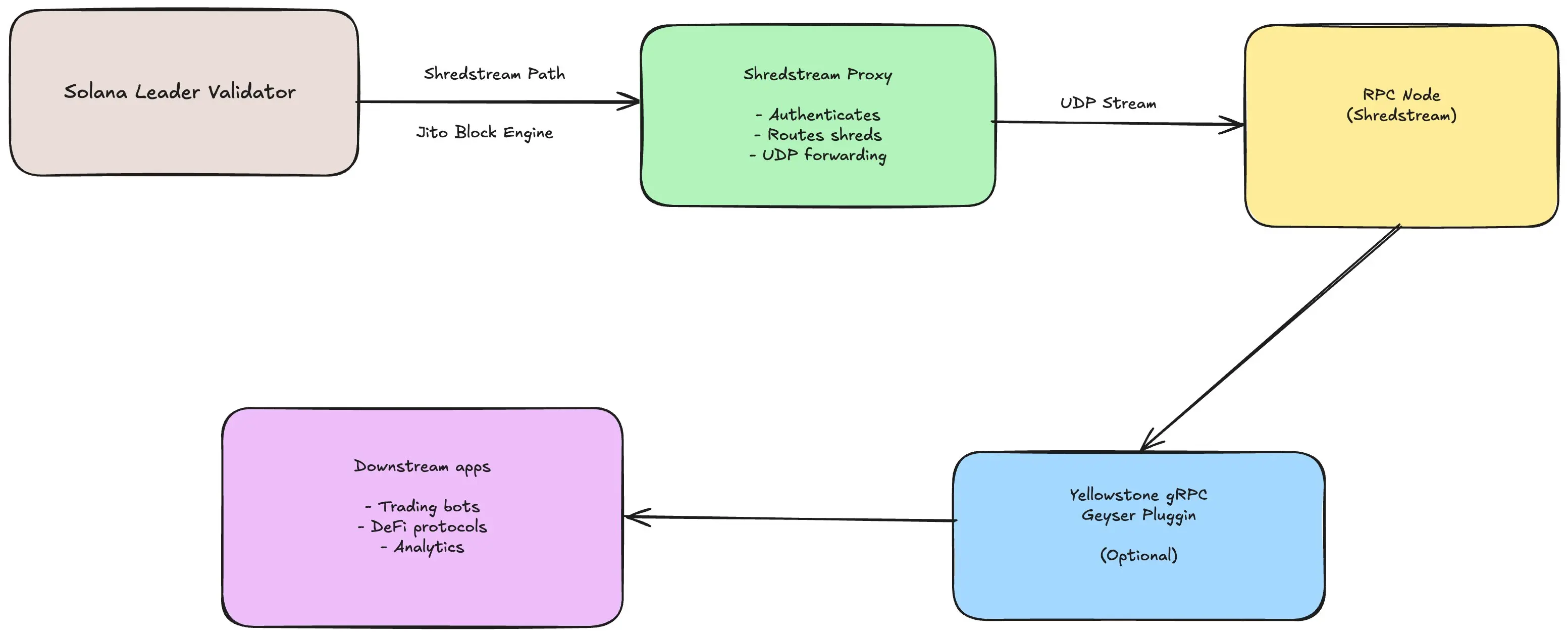
For a Solana RPC node or trader listening to ShredStream, block data arrives a few hops earlier than it normally would. According to a recent Chainstack guide, this can eliminate the “small but costly timing gaps” present in standard propagation - where an RPC might see a block “a few hundred milliseconds after they’re produced” via normal Turbine block propagation. By tapping directly into leaders, ShredStream provides steadier, lower-latency feeds (and also fewer missed slots due to delays).
- Latency Savings: The difference is significant. Validator firm Everstake measured that a typical public RPC feed has about ~400ms total delay (block production + Turbine propagation) on average, whereas using raw shred streams can cut that down to on the order of 10–50ms if you’re in a nearby region. In practice, their users see 100–400+ ms of latency improvement by using ShredStream. Jito’s docs similarly note that ShredStream “can save hundreds of milliseconds” in block delivery for high-frequency trading setups.
- Resilience for Remote Nodes: ShredStream also adds a redundant path. If a validator is in a geographic region that’s “far” in network terms, the normal Turbine path might be slow or prone to packet loss. A direct shred feed gives a backup source of truth and helps those nodes stay in sync. Jito specifically highlights that ShredStream provides “a redundant shred path for servers in remote locations, enhancing reliability for users in less connected regions”.
Trade-offs: Of course, subscribing to ShredStream means relying on an external block engine network (operated by Jito or others). It introduces some centralization (a closed relay delivering the data), which is acceptable for traders and RPC services but not something that can be baked into the trustless consensus. It’s a complement to Turbine, not a replacement – but it clearly demonstrates there’s demand to push propagation latency as low as possible.
JetStreamer: Pushing the Throughput Envelope
Another angle to consider is raw throughput: how much data can the network propagate if we really push the limits? JetStreamer is a tool from Anza that gives a glimpse of the upper bound. It’s not part of Solana’s consensus, but it streams historical ledger data at extreme speeds for indexing and backfilling purposes. Think of it as a “firehose” approach to Solana’s data.JetStreamer leverages an archive of the entire Solana ledger (Project Yellowstone’s Old Faithful archive) and streams it to clients at record speeds. In tests, JetStreamer achieved over 2.7 million transactions per second replay throughput on a 64-core machine with a 30 Gbps network link. This astonishing number (~2.7M TPS) is orders of magnitude beyond Solana’s live TPS, and it showcases the potential capacity when network IO is the only limit. As the JetStreamer team notes, “given the right hardware and network connection, Jetstreamer can stream data at over 2.7M TPS… Higher speeds are possible with better hardware”
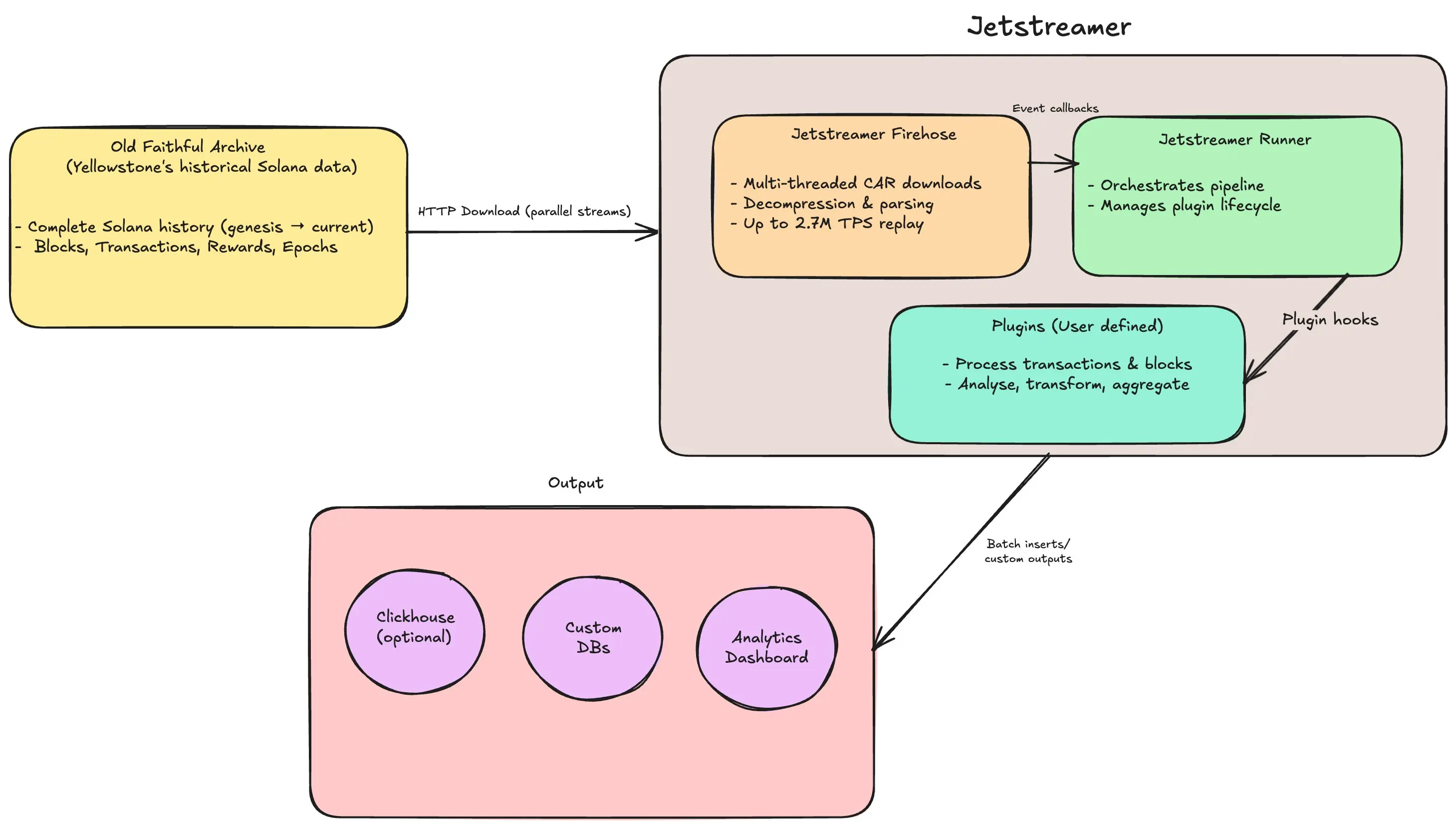
Why does this matter? It tells us that data propagation can scale – if you throw bandwidth and optimized code at it – far beyond today’s norms. Solana’s actual consensus isn’t doing 2.7M TPS (and doesn’t need to yet), but if someday it approaches that, the network layer must deliver. JetStreamer’s success hints that the software and network could handle much more throughput, but the bottleneck might soon become the P2P propagation protocol and node bandwidth. In other words, Solana could process more transactions if every node could receive all the data faster.It’s also a reminder that specialization helps: JetStreamer bypasses the normal P2P path by pulling from a data archive, similar conceptually to how a block engine or shred feed might bypass some live hops. The lesson is that with optimized data distribution, Solana’s performance ceiling can rise even further.
Limitations of the Current Stack
Despite Solana’s advanced design, there are inherent limitations and new pain points emerging as the network and its usage evolve. Here are the key issues where faster or better propagation is needed:
- Geographical Latency & Jitter: Solana is a global network. Validators in Europe vs Asia vs North America will inevitably see different propagation times. Turbine’s multi-hop tree means a block may traverse several relays to reach the far end of the world. If a block originates in Frankfurt and a validator is in Singapore, speed-of-light plus networking hops might add 150-200ms latency at best. In fact, measurements on a similar global setup (Optimum’s ETH test) show even an optimized protocol still sees ~150ms average and spikes to 200-250ms due to “geography and physics”. For Solana’s 400ms slots, that’s a big chunk. Standard Turbine propagation can be even slower for distant nodes or under network congestion. These delays don’t affect consensus finality per se, but they do matter for validators trying not to miss their voting window and for anyone needing real-time data.
- Packet Loss and Missing Shreds: UDP-based propagation means not every shred reaches every validator. Solana’s erasure coding helps – you don’t need 100% of shreds, just enough pieces to reconstruct the block. But if a validator misses too many shreds (due to network issues or a slow relay), it might fail to assemble the block in time and miss the slot. Missing slots means missed votes and lower rewards, and in extreme cases could stall the network if too many miss at once. Faster propagation can reduce these risks.
- Uneven Data Distribution & Fairness: The stake-weighted Turbine tree, while efficient, raises questions about fairness and centralization. High-stake validators get the data first by design. This gives them more time to vote and re-transmit, but it might also confer advantages in extracting MEV or reacting to pending blocks (since they see new transactions fractions of a second earlier).
- Scaling to Higher Throughput: Right now, Solana comfortably handles tens of thousands of TPS, with 1-block finality around 400-500ms. But future demands may push for even more throughput (consider the Firedancer validator client by Jump Crypto, which is optimized for 10 Gbps networking – implying the intent to significantly increase data flow). If Solana starts producing larger blocks or more blocks per second, the Turbine tree must carry a heavier load. Bandwidth could become a bottleneck for validators with less-than-datacenter connections. Already, a Solana node uses substantially more bandwidth than an Ethereum node, and not every validator can upgrade to 10 Gbps fiber easily. More efficient propagation (sending less duplicate data, smarter routing) will be needed to scale further without leaving smaller validators behind.
- Reliability Under Stress: Past Solana network hiccups (the outages in 2022-2023) had various causes, but one contributing factor can be propagation stress during high load. For instance, if the rate of incoming transactions exceeds the network’s ability to propagate and process blocks, validators can become overwhelmed or fall out of sync with the cluster. This can lead to degraded performance or even stalls. Strengthening the block propagation pipeline, such as improving deduplication and load-handling in Turbine, is essential for maintaining Solana’s robustness under pressure.
- Data Availability for Light Clients: (A quick aside) Turbine ensures every full validator gets all data, but it doesn’t support data availability sampling (DAS) for light clients. While not directly about speed, any evolution of Solana’s propagation to support light nodes might require new techniques (perhaps similar to Celestia’s DAS) that could also affect performance. It’s an open research area. An ideal solution would let even lightweight nodes quickly verify blocks without trusting others, all while maintaining Solana’s speed.
- Validator Decentralization at Scale: As Solana aims to maintain high throughput while expanding validator participation, propagation becomes a limiting factor for decentralization. Validators with low-bandwidth or geographically remote infrastructure often struggle to keep up with Turbine’s high data rates, especially under congestion or during blockstorms. Without improvements to bandwidth efficiency or dynamic relay selection, the network risks favoring well-connected validators in datacenters centralizing block access, retransmission power, and economic opportunity. Research into bandwidth-optimized propagation (e.g., stake-weight-aware QUIC streams, erasure-aware retransmission) and tools like the Firedancer client, which targets better performance on commodity hardware, are essential to support a globally diverse validator set.
In summary, Solana’s networking stack is near the cutting-edge, but not “complete.” The difference between a block reaching the first validator vs the last can be several hundred milliseconds.
Looking Ahead
Solana has always valued chain performance, and adding RLNC based propagation to the stack would be a major advancement in their IBRL agenda. Solana can either iterate on Turbine or incorporate new approaches. Exciting work by Optimum is already underway for this data propagation use case on Ethereum and we are exploring how it could be applied to Solana and Turbine. Our first product, mump2p uses, Random Linear Network Coding (RLNC) to P2P message propagation – essentially allowing nodes to re-encode and forward partial data on the fly, vastly improving bandwidth usage and fault tolerance.
- RLNC “Gossip” Explained: In mump2p, nodes don’t just forward the exact packets they received; they can mix (linearly combine) chunks of data and send those out. These coded shards are just as useful to reconstruct the original message as the originals were, as long as you gather enough unique pieces. The big benefit is that even if different nodes receive different subsets of shards, they can all contribute new combinations to spread the message further. No single shard is critical; any k out of n coded pieces allow recovery. This gives high loss tolerance and means propagation can continue quickly even in the face of packet drops. Also, because nodes can forward data before they have the whole block, it cuts down on latency – it’s possible to start relaying after receiving just a fraction of the message. RLNC’s composability also reduces shred duplication across the network since each coded piece is algebraically independent.
- RLNC codes have the unique advantage that intermediate nodes do not need to decode before forwarding. This on-the-fly recoding makes propagation resilient to partial data and removes the need to wait for full block reconstruction at each layer. In contrast, Turbine’s reliance on Reed-Solomon codes creates propagation stalls when intermediate nodes miss too many packets.
- Proven in Testnet: mump2p demonstrated on Ethereum’s testnet “Hoodi”, achieving ~150ms global block propagation, which is 5–6x faster than Ethereum’s normal gossip (which was ~0.8–1.0 seconds. The implication is that decentralized networking can approach the latencies of dedicated relay networks, by simply being smarter about how data is encoded and shared.
- Applicability to Solana: Solana already uses erasure coding at the block level; mump2p takes coding to the packet propagation level. If Solana integrated something like this for Turbine, it could further reduce propagation time and improve reliability. For example, instead of fixed Reed-Solomon data shreds that the leader computes, validators could continuously create new coded shreds as they forward data. That would make it much harder for a block to “get stuck” – even a validator who only got half the shreds could recode and pass them on. It might also reduce the total bandwidth needed, since fewer redundant packets would need to be sent compared to Turbine’s somewhat brute-force tree. In theory, Solana’s large blocks and fast schedule could greatly benefit from RLNC by cutting down on the wasted time and data during propagation. Because RLNC only needs to cross the network’s “min-cut,” not every branch of the tree, it can tolerate partial relay failures far better than a Turbine-style tree that depends on full node reliability at each layer.
- Complementary vs Alternative: It’s worth noting that Solana could incorporate these improvements in stages. mump2p might first live as an overlay network (similar to how ShredStream is an overlay) that feeds blocks faster to those who opt in.
- Focus on Reliability: Beyond just raw speed, these innovations also target network resilience. With faster propagation, validators have more breathing room to process and vote on a block. (On Ethereum, a 6x speedup gave validators noticeable extra time to produce attestations; on Solana, any saved milliseconds can be used to handle more transactions or reduce the chance of falling behind). Also, by reducing propagation variance (the long tail of slow block delivery), the network becomes more predictable and less prone to forks or timeouts. In benchmark models, RLNC with the same redundancy as RS shows significantly lower residual loss and up to 4x lower latency at 1–5% network loss rates . These benefits compound at greater network depth or when using mixed transports like UDP and QUIC.
To learn more about Optimum and our first product, mump2p, check out the docs.



